


YouTube fail videos reveal a major blind spot for leading AI models: they struggle with surprises and rarely reconsider their first impressions. Even advanced systems like GPT-4o stumble over simple plot twists.
Researchers from the University of British Columbia, the Vector Institute for AI, and Nanyang Technological University put top AI models through their paces using more than 1,600 YouTube fail videos from the Oops! dataset.
The team created a new benchmark called BlackSwanSuite to test how well these systems handle unexpected events. Like people, the AI models are fooled by surprising moments—but unlike people, they refuse to change their minds, even after seeing what really happened.
One example: a man swings a pillow near a Christmas tree. The AI assumes he’s aiming at someone nearby. In reality, the pillow knocks ornaments off the tree, which then hit a woman. Even after watching the whole video, the AI sticks to its original, incorrect guess.
The videos span a range of categories, with most featuring traffic accidents (24 percent), children’s mishaps (24 percent), or pool accidents (16 percent). What unites them all is an unpredictable twist that even people often miss.
Three types of tasks
Each video is split into three segments: the setup, the surprise, and the aftermath. The benchmark challenges LLMs with different tasks for each stage. In the “Forecaster” task, the AI only sees the start of the video and tries to predict what comes next. The “Detective” task shows only the beginning and end, asking the AI to explain what happened in between. The “Reporter” task gives the AI the full video and checks whether it can update its assumptions after seeing the full story.

The tests covered both closed models like GPT-4o and Gemini 1.5 Pro, as well as open-source systems such as LLaVA-Video, VILA, VideoChat2, and VideoLLaMA 2. The results highlight glaring weaknesses. On the detective task, GPT-4o answered correctly just 65 percent of the time. By comparison, humans got 90 percent right.
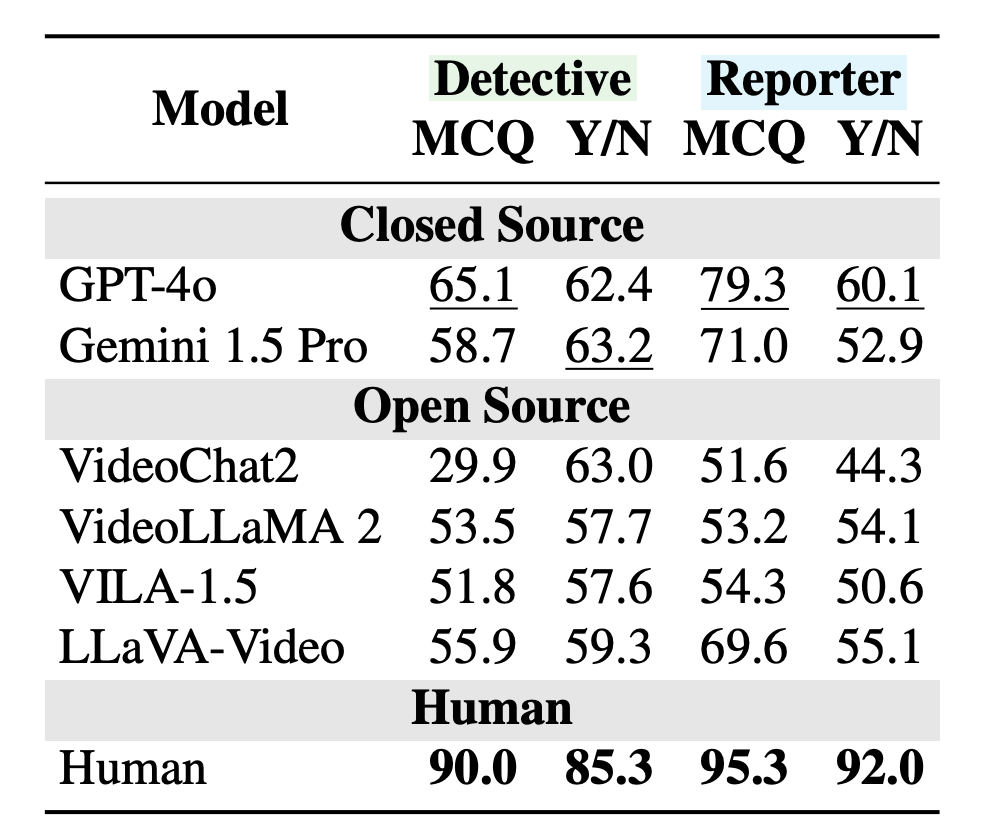
The gap widened even further when models needed to reconsider their initial guesses. When asked to revisit their predictions after seeing the entire video, GPT-4o managed only 60 percent accuracy – 32 percentage points behind humans (92 percent). The systems tended to double down on their first impressions, ignoring new evidence.
Other models, like Gemini 1.5 Pro and LLaVA-Video, showed the same pattern. According to the researchers, performance dropped sharply on videos that even people found tricky the first time through.
Garbage trucks don’t drop trees, do they?
The root of the problem lies in how these AI models are trained. They learn by spotting patterns in millions of videos and expect those patterns to repeat. So when a garbage truck drops a tree instead of picking up trash, the AI gets confused—it has no pattern for that.

To pinpoint the issue, the team tried swapping out the AI’s video perception for detailed human-written descriptions of the scenes. This boosted LLaVA-Video’s performance by 6.4 percent. Adding even more explanations bumped it up by another 3.6 percent, for a total gain of 10 percent.
Ironically, this only underscores the models’ weakness: If the AI performs well only when humans do the perceptual heavy lifting, it fails at “seeing” and “understanding” before any real reasoning starts.
Humans, by contrast, are quick to rethink their assumptions when new information appears. Current AI models lack this mental flexibility.
This flaw could have serious consequences for real-world applications like self-driving cars and autonomous systems. Life is full of surprises: children dash into the street, objects fall off trucks, and other drivers do the unexpected.
The research team has made the benchmark available on Github and Hugging Face. They hope others will use it to test and improve their own AI models. As long as leading systems are tripped up by simple fail videos, they’re not ready for the unpredictability of the real world.










