


A new AI system called StreamDiT can generate livestream videos from text descriptions, opening up new possibilities for gaming and interactive media.
Developed by researchers at Meta and the University of California, Berkeley, StreamDiT creates videos in real time at 16 frames per second using a single high-end GPU. The model, with 4 billion parameters, outputs videos at 512p resolution. Unlike previous methods that generate full video clips before playback, StreamDiT produces video streams live, frame by frame.
Video: Kodaira et al.
The team showcased various use cases. StreamDiT can generate minute-long videos on the fly, respond to interactive prompts, and even edit existing videos in real time. In one demo, a pig in a video was transformed into a cat while the background stayed the same.

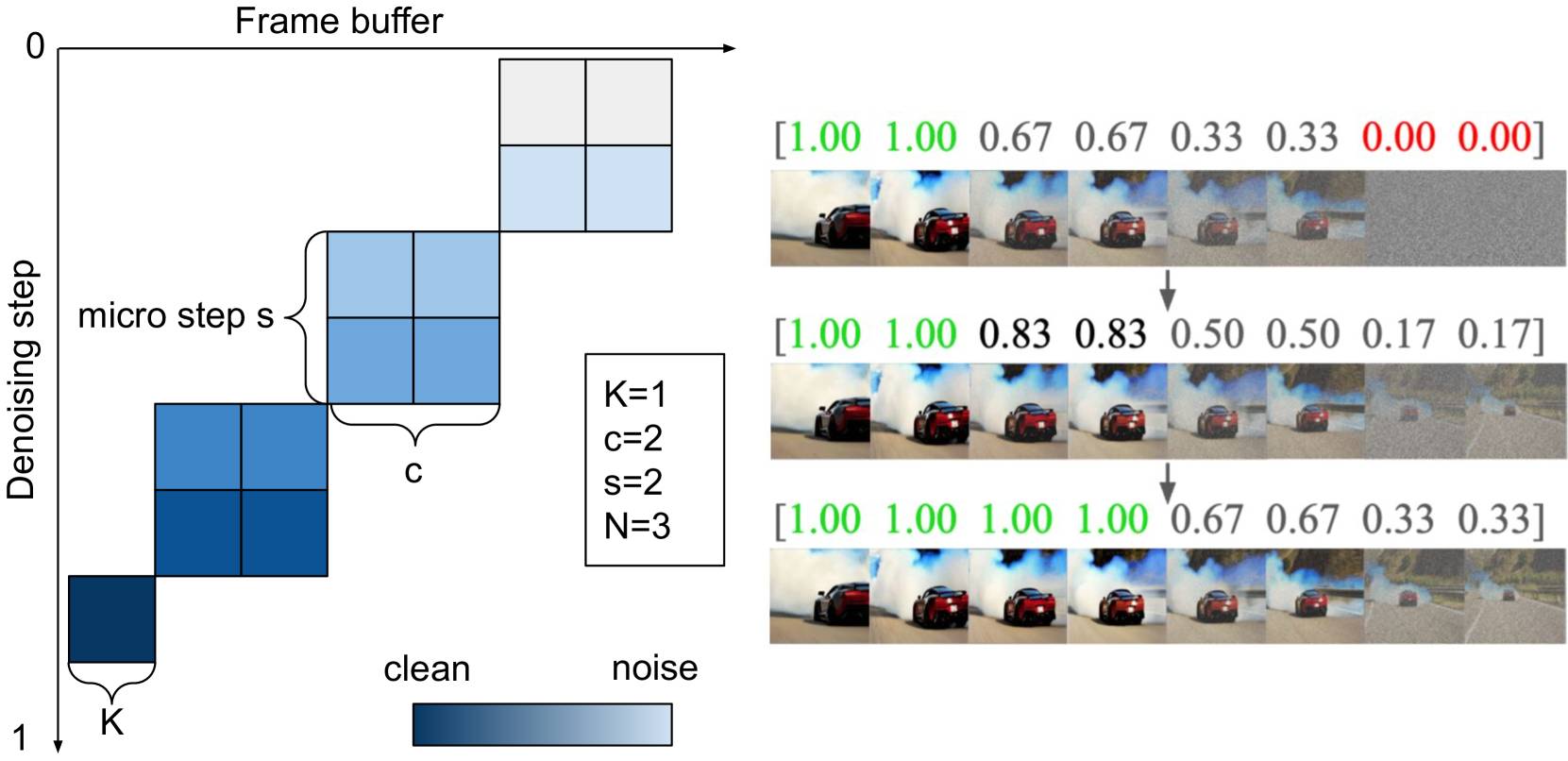
The system relies on a custom architecture built for speed. StreamDiT uses a moving buffer to process multiple frames simultaneously, working on the next frame while outputting the previous one. New frames start out noisy but are gradually refined until they are ready for display. According to the paper, the system takes about half a second to generate two frames, producing eight finished images after processing.
Training for versatility
The training process was designed to improve versatility. Instead of focusing on a single video creation method, the model was trained with several approaches, using 3,000 high-quality videos and a larger dataset of 2.6 million videos. Training took place on 128 Nvidia H100 GPUs. The researchers found that mixing chunk sizes from 1 to 16 frames produced the best results.
To achieve real-time performance, the team introduced an acceleration technique that cuts the number of required calculation steps from 128 to just 8, with minimal impact on image quality. The architecture is also optimized for efficiency: rather than having every image element interact with all others, information is exchanged only between local regions.
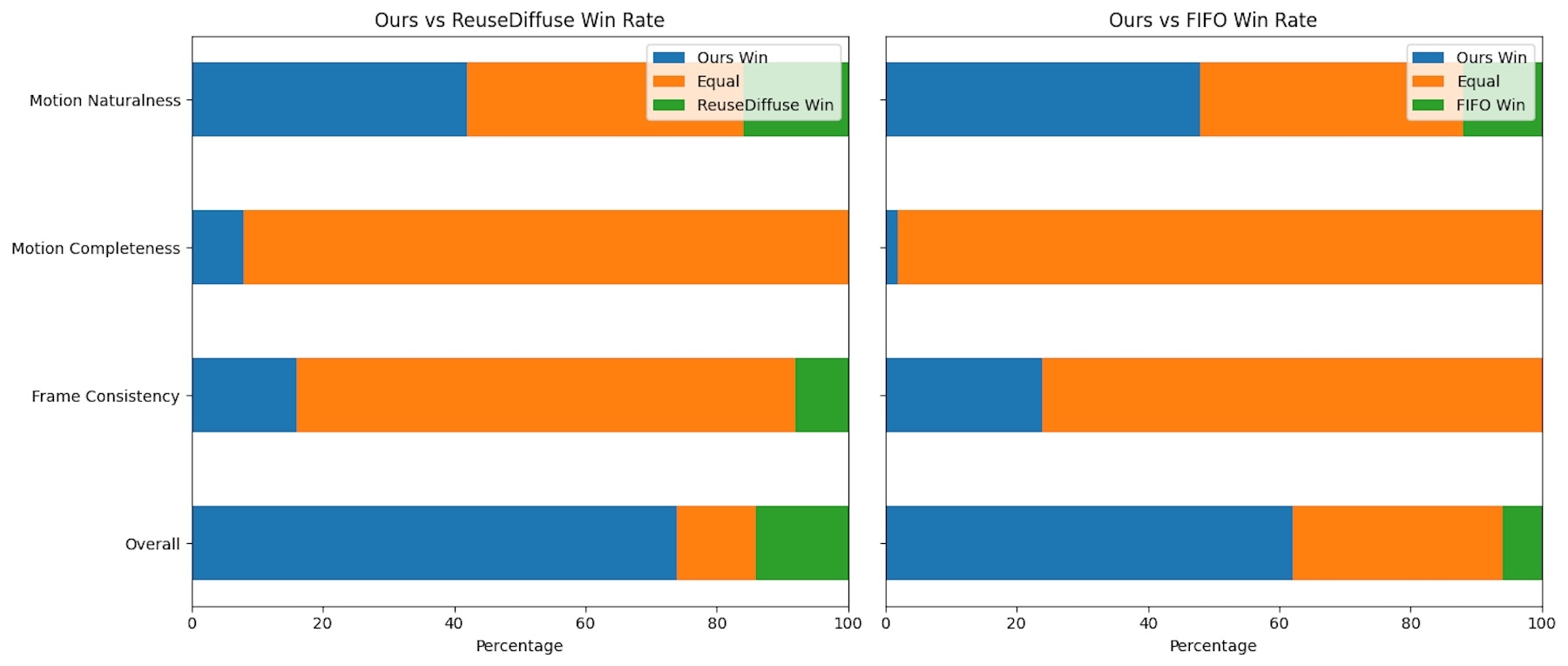
In head-to-head comparisons, StreamDiT outperformed existing methods like ReuseDiffuse and FIFO diffusion, especially for videos with a lot of movement. While other models tended to create static scenes, StreamDiT generated more dynamic and natural motion.
Human raters evaluated the system’s performance on fluidity of motion, completeness of animation, consistency across frames, and overall quality. In every category, StreamDiT came out on top when tested on eight-second, 512p videos.
Bigger model, better quality—but slower
The team also experimented with a much larger 30-billion-parameter model, which delivered even higher video quality, though it wasn’t fast enough for real-time use. The results suggest the approach can scale to larger systems.
Video: Kodaira et al.
Some limitations remain, including StreamDiT’s limited ability to “remember” earlier parts of a video and occasional visible transitions between sections. The researchers say they are working on solutions.
Other companies are also exploring real-time AI video generation. Odyssey, for example, recently introduced an autoregressive world model that adapts video frame by frame in response to user input, making interactive experiences more accessible.










