

Moonshot AI from China has launched Kimi-K2, a new open-weight large language model designed to rival top proprietary models like Claude Sonnet 4 and GPT-4.1, without a dedicated reasoning module—marking a moment reminiscent of Deepseek’s release.
Moonshot AI, founded in 2023, built Kimi-K2 as a mixture-of-experts model with a massive one trillion parameters, activating 32 billion per inference. The open weights make it accessible for research, fine-tuning, and custom applications.
On standard LLM benchmarks, Kimi-K2-Instruct—the version optimized for real-world use—lands in the same league as leading closed models. On SWE-bench Verified, it scores 65.8 percent in agent mode, just behind Claude Sonnet 4 and well ahead of GPT-4.1 (54.6 percent). The benchmark tests whether a model can spot and patch real code errors in open-source projects.
Kimi-K2 also leads the pack on LiveCodeBench (53.7 percent) and OJBench (27.1 percent) without a reasoning module. These tests measure how well language models tackle programming problems—LiveCodeBench interactively, OJBench as traditional competition tasks.
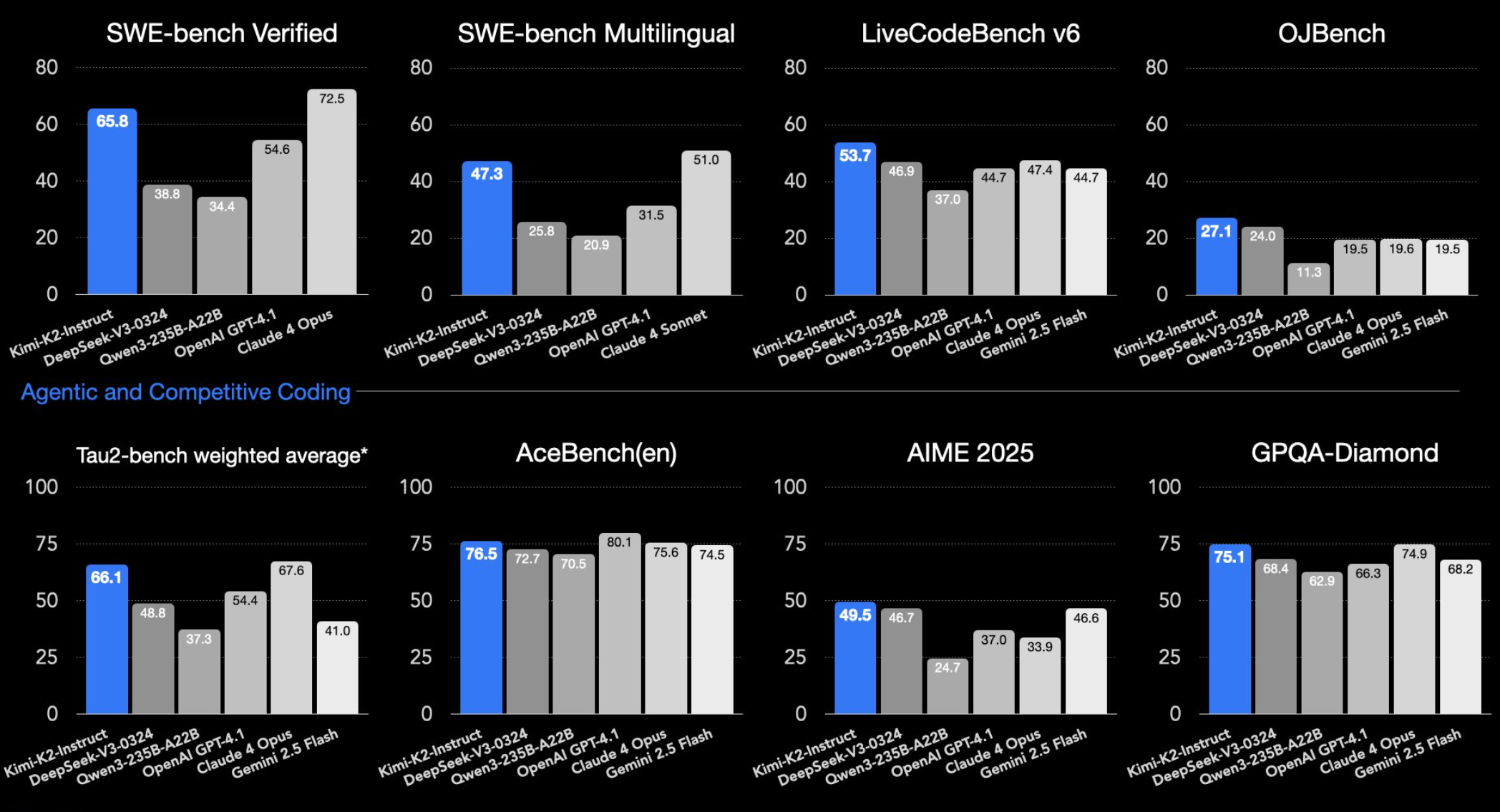
Kimi-K2 stands out in math and science tasks as well. In benchmarks like AIME, GPQA-Diamond, and MATH-500, it outperforms its competitors. It also ranks among the top models on multilingual tests such as MMLU-Pro. Moonshot AI showcases Kimi-K2’s coding capabilities on X.
2. a ball bouncing in hexagon pic.twitter.com/DhicknAtd7
– Kimi.ai (@Kimi_Moonshot) July 11, 2025
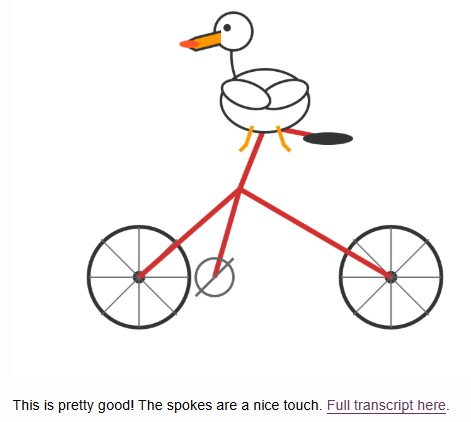
In an unofficial test by Simon Willison, Kimi-K2 successfully generated an SVG of a pelican on a bicycle—a task that often trips up other models, which tend to produce only abstract shapes.
Built for agentic workflows
Moonshot AI says Kimi-K2 is specifically for agentic applications. The model can execute commands, call external tools, generate and debug code, and handle complex, multi-step tasks independently.
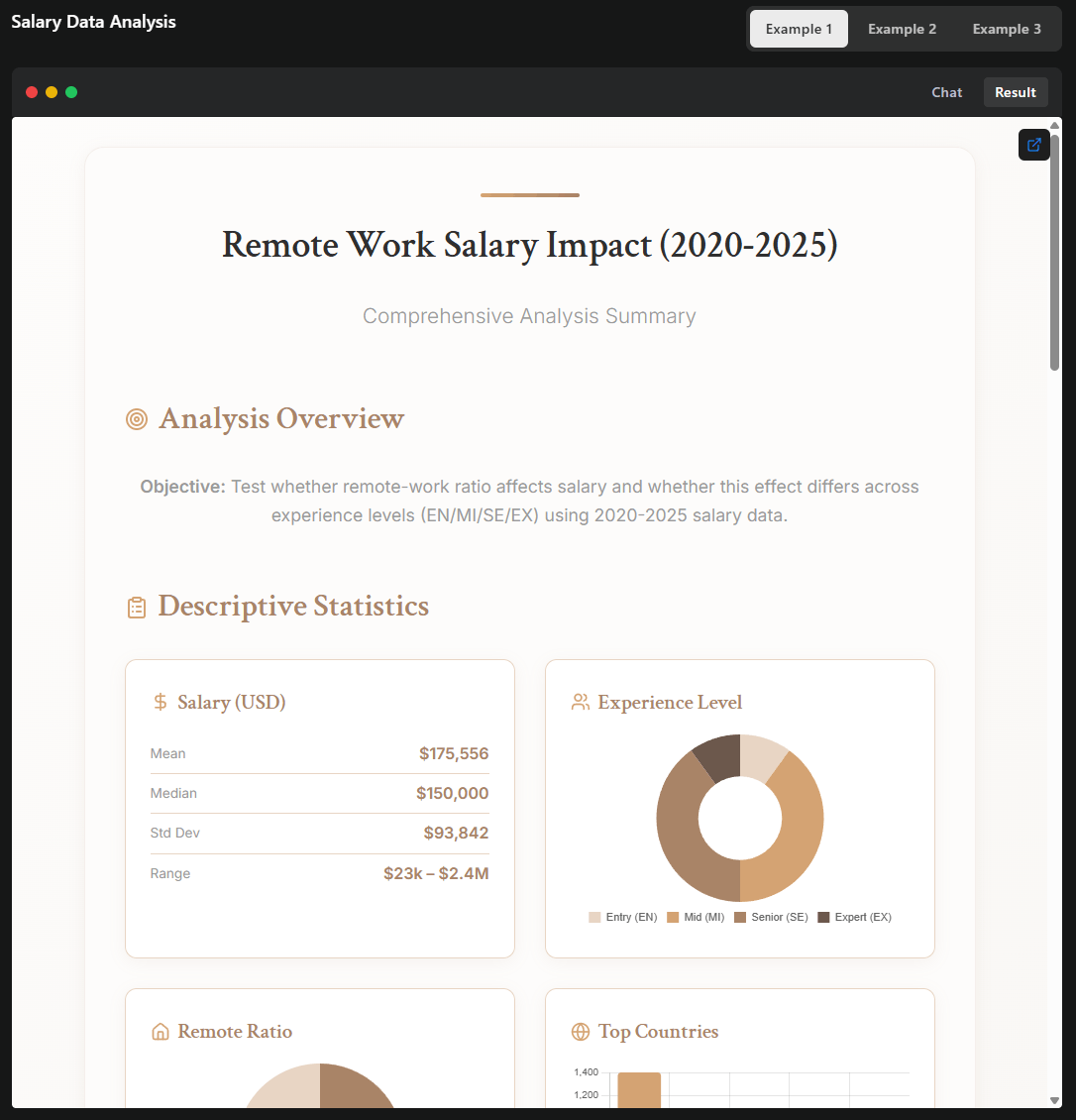
In one demonstration, Kimi-K2 analyzed salary data for remote jobs, performed statistical evaluations, and created an interactive HTML page with a customizable recommendation tool—all within a single agentic process.
There are still some limits. According to Moonshot AI, highly complex tasks or unclear tool requirements can sometimes result in lengthy or incomplete outputs. The model also performs better in ongoing agent-based sessions than in one-off, single-shot prompts.
Kimi-K2 was trained on 15.5 trillion tokens with a new training algorithm called MuonClip, which maintains stability by regularly scaling key attention components. Moonshot AI reports the process was stable throughout—which is not a given at this scale.
Flexible deployment, but hefty requirements
Kimi-K2 is available in two versions: Kimi-K2-Base for research and custom fine-tuning, and Kimi-K2-Instruct for general chat and agent tasks. Both models can be accessed through an OpenAI-compatible API on the Moonshot AI platform. Pricing is tiered: $0.15 per million input tokens for cache hits, $0.60 for cache misses, and $2.50 per million output tokens.
You can also run Kimi-K2 locally using inference engines like vLLM, SGLang, KTransformers, or TensorRT-LLM. Setup instructions are available in the official GitHub repository.
The license is based on MIT, with one extra requirement: if you deploy Kimi-K2 in a product with over 100 million monthly active users or more than $20 million in monthly revenue, the name “Kimi K2” must be clearly visible in the user interface. For most companies, this won’t be a problem.
Running Kimi-K2 locally or at scale is hardware-intensive. With a trillion parameters and 32 billion activated per inference, the model requires powerful GPUs for production use or on-prem hosting, likely multiple NVIDIA B200 GPUs or a multinode setup on Nvidia’s Hopper architecture. According to Apple’s MLX developer Awni Hannun, a 4-bit quantized version can run on two Apple M3 Ultra machines with 512 GB RAM each.
Earlier this year, Moonshot AI also introduced a reasoning model that matches OpenAI’s o1, as well as a strong vision model released in April.










