

French AI company Mistral unveils Voxtral, an open-source speech understanding model that aims to replace proprietary solutions at less than half the cost.
The Voxtral models come in two versions: a 24B variant for production applications and a compact 3B model for local and edge deployments. Both support a 32,000-token context window, which Mistral says can handle audio files up to 30 minutes for transcription or 40 minutes for comprehension tasks.
Unlike basic transcription tools, Voxtral builds in Q&A and summarization features without requiring separate speech recognition and language models. It also lets users trigger backend functions directly through voice commands by automatically translating spoken requests into API calls.
The models support automatic speech recognition in English, Spanish, French, Portuguese, Hindi, German, Dutch and Italian while retaining the text comprehension capabilities of Mistral Small 3.1‘s language model backbone.
Benchmark performance exceeds competition
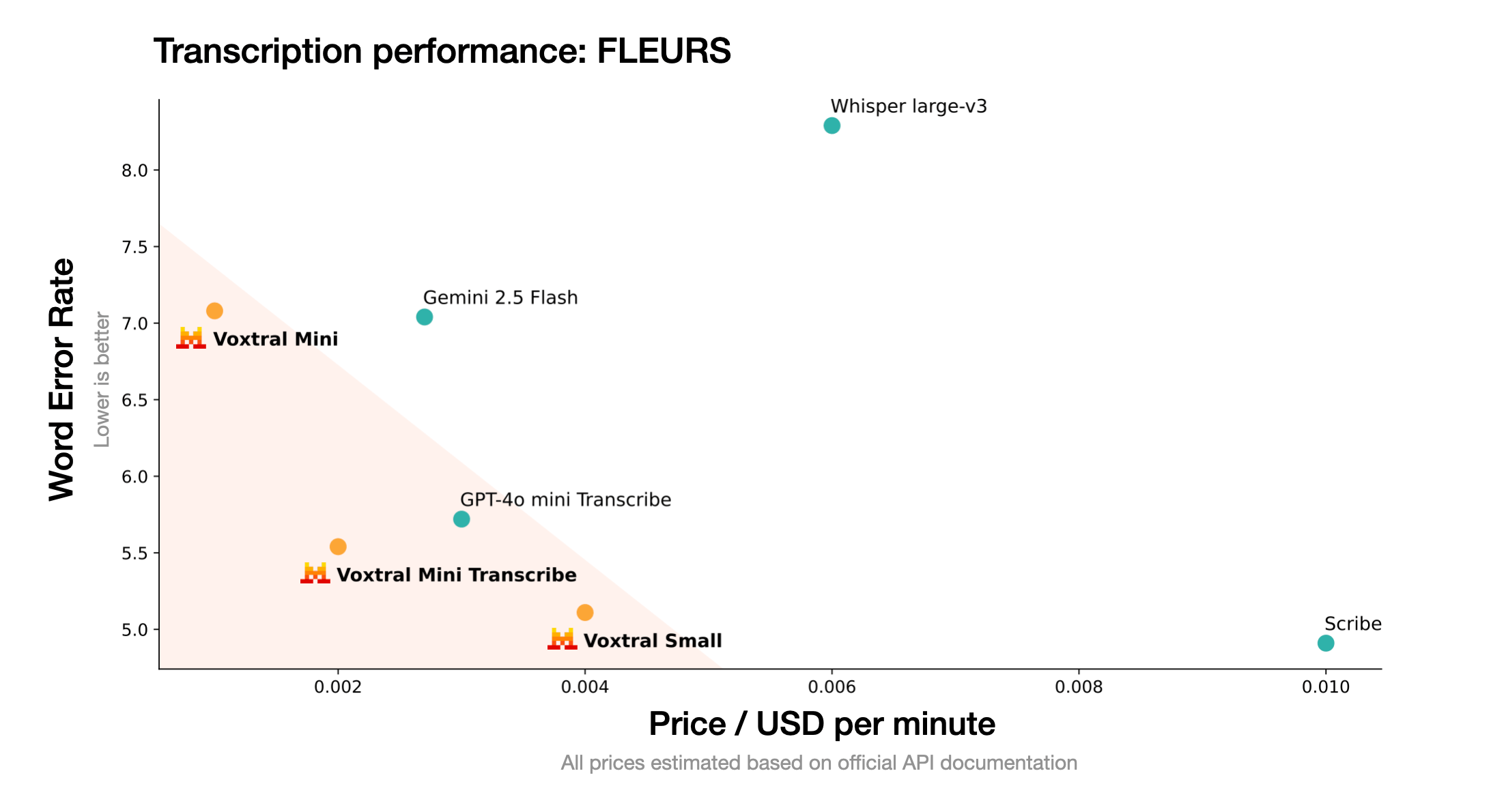
Mistral’s tests show Voxtral Small outperforming leading open-source model Whisper large-v3, along with GPT-4o mini Transcribe and Gemini 2.5 Flash across all tested tasks. For English short-form tasks and Mozilla’s Common Voice benchmark, it reportedly beats ElevenLabs Scribe – currently one of the strongest performers.
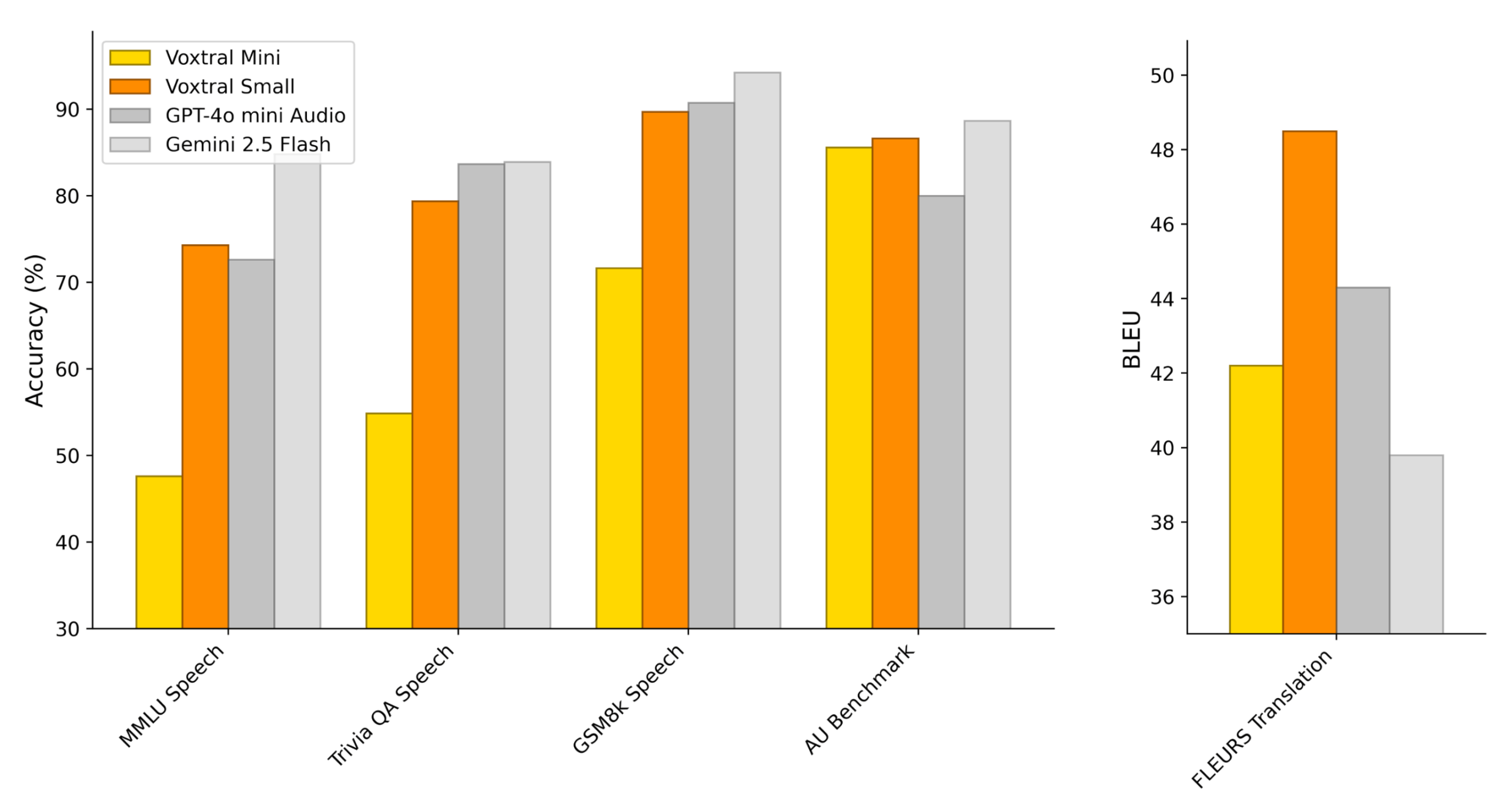
In the FLEURS multilingual speech recognition benchmark, Voxtral Small allegedly surpasses Whisper in all nine tested languages. For audio comprehension tasks, it performs comparably to GPT-4o-mini and Gemini 2.5 Flash while delivering state-of-the-art results in speech translation.
Pricing undercuts proprietary alternatives
Mistral positions Voxtral as a budget-friendly option, with API pricing starting at $0.001 per minute. The company claims Voxtral Mini Transcribe outperforms OpenAI’s Whisper at less than half the cost for price-sensitive applications, while Voxtral Small matches ElevenLabs Scribe’s performance at similar savings.
Enterprise features include private deployment options for regulated industries and domain-specific fine-tuning. Coming updates will add speaker segmentation, audio markups for age/emotion detection, and word-level timestamps.
Coming to Le Chat’s Voice Mode
Both Voxtral versions are available under Apache-2.0 license for download on Hugging Face, with Mistral also offering API access. The models will power the Voice Mode in Le Chat, which rolls out to all users in coming weeks.










